Firebase 요금 폭탄 맞고 Supabase로 갈아탄 뒤 직접 겪은 생생한 경험담
제가 개인 뉴스 크롤링 봇을 돌리는데, 갑자기 트래픽이 폭발하면서 Firebase Firestore에서 읽기 요청이 한 달에 100만 건을 훌쩍 넘겼습니다. 청구서를 보고 깜짝 놀랐죠. 평소보다 3배 넘는 30달러가 청구됐거든요. Firestore 과금 구조가 읽기·쓰기 단위별이라서, 사소하게 조회 패턴 조금만 바뀌어도 비용이 확 올라가는 걸 몸소 느꼈습니다. 특히 데이터가 쌓이면서 단순 조회만 해도 비용이 눈덩이처럼 불어나는 게 미칠 노릇이었어요. 비용 관리할 제대로 된 방법이 없어서 한참 고민하다가, 오픈소스 기반인 Supabase를 알게 됐습니다. PostgreSQL 기반인데도 Firebase처럼 편리한 기능들이 많아서 직접 써보기로 했죠.
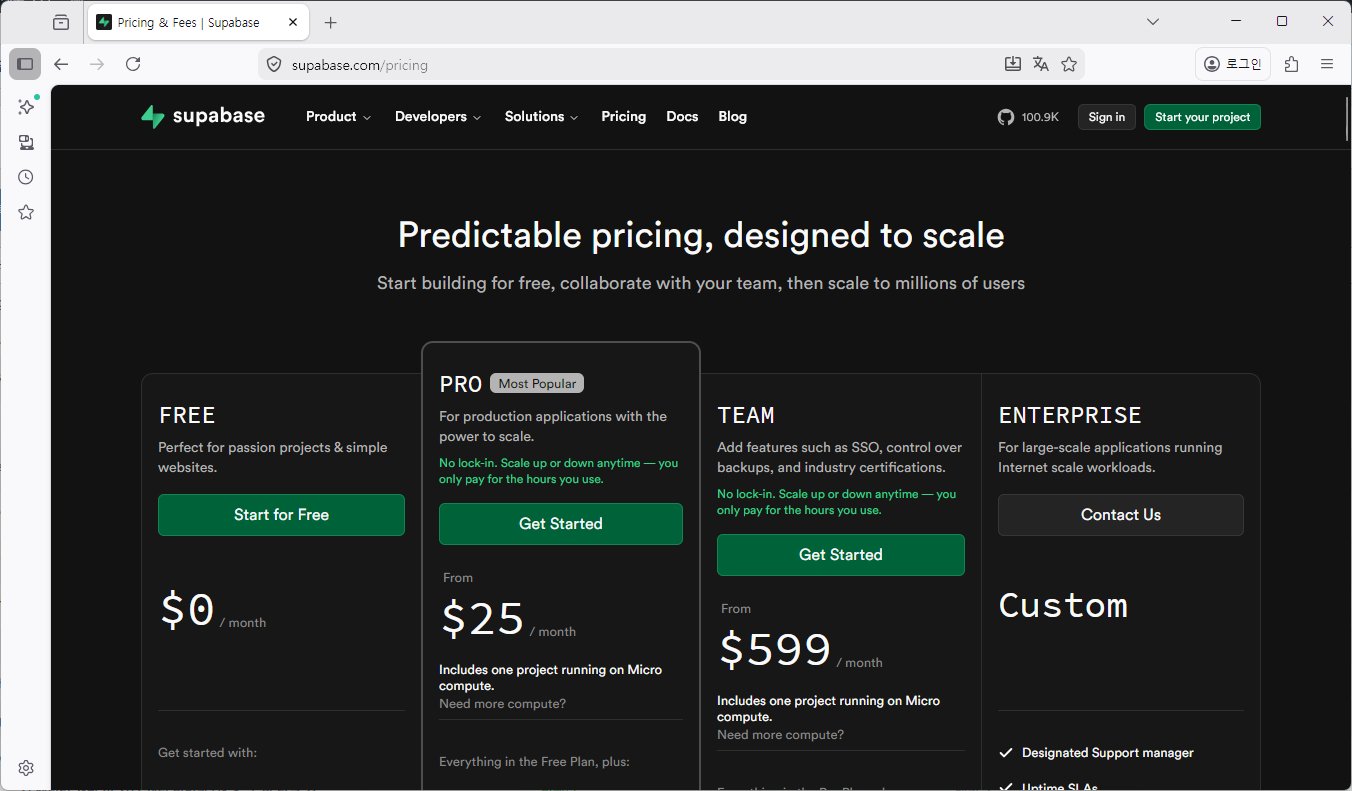
Supabase는 단순 NoSQL이 아니라 관계형 DB인 PostgreSQL이라 데이터 정합성 챙기고 복잡한 쿼리도 훨씬 쉽게 처리할 수 있었습니다. 게다가 인증, 스토리지, 실시간 구독 기능을 한곳에 몰아둬서 다른 서비스 연동하느라 고생할 일도 줄었어요. 무료 플랜에선 데이터베이스 500MB, 파일 스토리지 1GB, 그리고 월 50만 건 Edge Function 호출까지 줘서 개인 프로젝트에는 충분한 자원이었고요. 다만, 이 부분은 진짜 꿀팁인데, API 호출이 7일 동안 없으면 프로젝트가 자동으로 일시 정지돼서 한 번은 모바일 환경에서 헬스체크 설정을 깜빡해 서비스가 멈춰서 짜증이 폭발한 적이 있습니다. 그래서 꼭 자동 헬스체크 설정을 해두는 걸 추천합니다. 이거 안 하면 진짜 낭패 봐요.
목차
- 1. Supabase 무료 플랜 상세 조건과 Firebase와의 차이점
- 2. Supabase 프로젝트 생성부터 API 키 발급까지 단계별 절차
- 3. 파이썬으로 Supabase CRUD 구현 실전 코드
- 4. 실제 마주친 에러 2가지와 대응 방법
- 5. 자동화 봇과 Supabase 연동 시 체감하는 변화
1. Supabase 무료 플랜 상세 조건과 Firebase와의 차이점
제가 직접 써본 Supabase 무료 플랜은 개인 프로젝트에 딱 맞는 조건이었습니다. 데이터베이스 용량이 500MB, 파일 스토리지도 1GB까지 무료로 쓸 수 있어서 작은 서비스 운영에는 충분했어요. 특히 월 50만 건이나 되는 Edge Function 호출이 무료라는 점, 이건 진짜 꿀팁입니다. 서버리스 함수 쓰면서 청구서 걱정 없이 실험할 수 있으니까요. API 요청 횟수가 무제한이라 트래픽이 갑자기 터져도 걱정이 덜했는데, 이 부분은 Firebase와 큰 차이라고 느꼈습니다. 다만 한 가지 불편했던 건, 프로젝트가 7일 동안 API 호출이나 접속이 없으면 자동으로 일시 정지된다는 점입니다. 제가 이걸 몰라서 한참 헬스체크 안 돌리다가 서비스가 멈춰서 짜증났던 기억이 있네요. 그래서 GitHub Actions나 n8n 같은 도구로 주기적으로 SELECT 1 쿼리를 보내는 걸 꼭 설정했습니다. 이걸 안 하면 무료 플랜이지만 사실상 쓸 수 없는 상황이 되니까요.
Firebase와 Supabase를 직접 비교해보면, 가장 크게 와 닿는 차이는 데이터 구조와 과금 방식이었습니다. Firebase는 NoSQL 문서 기반이라 데이터 쌓이는 게 직관적이지 않고, 복잡한 쿼리 작성이 불편했어요. 그리고 읽기·쓰기 단위별 과금이라 트래픽이 조금만 불어나도 비용 폭탄 맞기가 쉬웠습니다. 실제로 제가 Firebase 쓸 때 요금이 한 달 새에 너무 올라서 한참 관리하느라 골머리를 앓았죠. 반면 Supabase는 PostgreSQL 기반이라 SQL 쿼리로 자유롭게 JOIN이나 트랜잭션, 인덱스 조작이 가능했고, 용량 기준으로 과금해서 트래픽이 급증해도 월별 요금 변동이 덜했습니다. SQL에 익숙한 개발자라면 관리하기 훨씬 편하다고 생각합니다. 다만, Supabase가 완벽한 건 아니라서, 무료 플랜에서 간혹 API 호출 지연이나 일시 정지 기능 때문에 신경 써야 하는 부분도 있다는 점은 명심하세요.
2. Supabase 프로젝트 생성부터 API 키 발급까지 단계별 절차
계정 생성 및 프로젝트 셋업
제가 직접 supabase.com에 접속해 구글 계정으로 가입했는데, 가입 절차가 의외로 단순해서 신경 쓸 것 없이 바로 대시보드로 넘어갔습니다. 대시보드에서 [New Project] 버튼을 눌러 프로젝트 이름과 데이터베이스 비밀번호, 리전을 설정하는데, 비밀번호는 한 번 정하면 바꿀 수 없으니 강력한 걸로 골라야 합니다. 저는 이 부분을 소홀히 했다가 나중에 다시 만들게 돼서 꽤 귀찮았어요. 리전은 국내 사용자라면 Northeast Asia (Seoul)로 꼭 선택하세요. 직접 써보니 이 리전이 아니면 응답 속도가 확실히 느려서 답답했습니다. 프로젝트 생성 과정은 약 2분 정도 걸리는데, 그 시간 동안 기다리면서 뭔가 더 할 수 없다는 점이 좀 지루하더군요. 그래도 서버 세팅이 복잡하지 않아서 신기했습니다.
API 키와 URL 확인
프로젝트가 만들어지고 나면 좌측 메뉴에서 [Project Settings] > [API] 탭으로 들어가면 API를 쓸 때 필요한 두 가지 핵심 정보를 확인할 수 있습니다. Project URL은 데이터베이스와 통신하려면 꼭 필요하고, anon public 키는 클라이언트에서 쓰는 공개용 API 키입니다. 한 번은 이 키를 잘못 노출해서 당황한 적 있는데, service_role 키는 반드시 서버 사이드에서만 써야 해서 절대 깃허브 같은 공개 저장소에 올리면 안 됩니다. 저는 환경변수 파일인 .env에 이 두 값을 안전하게 저장해서, 파이썬 애플리케이션에서 불러오는 방식으로 작업했는데, 이렇게 해야 키 노출 위험을 줄일 수 있더라고요.
SUPABASE_URL=https://프로젝트ID.supabase.co
SUPABASE_KEY=여기에_anon_public_키테이블 생성: SQL 에디터 활용
제가 Supabase 대시보드에서 직접 SQL Editor를 이용해 테이블을 만드는 걸 시도해봤는데, 이 방법이 의외로 직관적이라 마음에 들었습니다. 특히 뉴스 크롤링 데이터를 저장하려고 테이블 구조를 짤 때 PostgreSQL의 배열 타입을 쓸 수 있다는 점은 정말 편리했어요. 예를 들어, 키워드 여러 개를 한 컬럼에 배열로 저장할 수 있어서 따로 연결 테이블 만들 필요가 없으니 작업이 훨씬 간단해졌습니다. 다만, URL 중복 삽입을 막으려고 고유 인덱스를 꼭 설정해야 하는데, 저는 이걸 깜빡했다가 나중에 삽질한 적 있어서 이 부분은 꼭 신경 써야 합니다. SQL 문을 실행하자마자 바로 테이블이 생성돼서 별도의 복잡한 마이그레이션 도구를 설치할 필요가 없다는 점은 정말 편했지만, 모바일에서 가끔 SQL Editor가 제대로 안 먹히는 경우가 있어서 그 부분은 좀 답답했어요.
CREATE TABLE articles (
id BIGSERIAL PRIMARY KEY,
title TEXT NOT NULL,
url TEXT UNIQUE NOT NULL,
summary TEXT,
keywords TEXT[], -- 배열 타입 지원
sentiment TEXT,
source_file TEXT,
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- 중복 URL 삽입 방지 인덱스
CREATE UNIQUE INDEX articles_url_idx ON articles(url);3. 파이썬으로 Supabase CRUD 구현 실전 코드
설치 및 클라이언트 초기화
제가 직접 Supabase 파이썬 SDK를 써보니, python-dotenv 패키지로 환경변수를 관리하는 과정에서 의외로 삽질이 많았습니다. 특히 .env 파일 경로나 변수명이 조금만 틀려도 클라이언트가 제대로 초기화되지 않아 한참 헤맸거든요. 이 부분을 꼼꼼히 체크하지 않으면 며칠을 허비할 수도 있으니, 꼭 변수명과 경로를 재확인하시길 권합니다.
pip install supabase python-dotenvimport os
from supabase import create_client, Client
from dotenv import load_dotenv
load_dotenv()
supabase: Client = create_client(
os.getenv("SUPABASE_URL"),
os.getenv("SUPABASE_KEY")
)데이터 삽입 (Insert)
제가 운영하는 자동 뉴스 수집 봇에서 Gemini API로 받은 JSON 데이터를 Supabase에 바로 넣어봤는데, upsert 메서드는 진짜 신의 한 수였습니다. URL 중복이 문제라 삽입에 실패하는 일이 잦았는데, 이 메서드는 URL이 같으면 기존 데이터는 업데이트하고, 없으면 새로 삽입해버리니까 삽입 실패 걱정을 덜었어요. 근데 처음 적용할 때는 on_conflict 옵션을 잘못 써서 삽입이 아예 안 되서 한참 고생했던 기억이 납니다. 이런 부분은 문서랑 좀 더 친절하게 설명해주면 좋겠어요.
def save_article(article_data: dict) -> dict:
"""분석된 기사 데이터를 Supabase에 저장 (중복 URL은 업데이트)"""
response = supabase.table("articles").upsert(
article_data,
on_conflict="url" # URL 중복 시 나머지 필드 업데이트
).execute()
return response.data
# 사용 예시 — Gemini API로 추출한 데이터 그대로 저장
article = {
"title": "OpenAI, GPT-5 정식 출시 발표",
"url": "https://example.com/news/123",
"summary": "OpenAI가 차세대 모델 GPT-5를 공개했다. 추론 능력이 대폭 향상됐다.",
"keywords": ["OpenAI", "GPT-5", "AI"],
"sentiment": "긍정"
}
saved = save_article(article)
print(f"저장 완료: ID {saved[0]['id']}")데이터 조회 (Select) 및 필터링
제가 Supabase 파이썬 SDK를 직접 써보면서 느낀 건, SQL 문법을 몰라도 메서드 체이닝 방식 덕분에 쿼리를 훨씬 쉽게 짤 수 있다는 점이었습니다. 특히 .eq(), .gte(), .order() 같은 메서드를 연달아 붙여 쓰면 조건을 직관적으로 조합할 수 있는데, 이 부분은 솔직히 처음엔 꽤 신선했어요. 저는 SQL을 꽤 오래 써왔지만, 복잡한 쿼리 쓸 때마다 문법 헷갈려서 한참 헤맬 때가 많았거든요.
그런데 막상 써보니 모바일 환경에서는 이 체인 구문이 꼬여서 에러가 나는 일이 여러 번 있었어요. 특히 필터를 여러 개 걸면 의도한 대로 결과가 안 나오거나, 심지어 쿼리가 아예 실패하는 경우도 있어서 한참 디버깅하느라 시간을 날리기도 했습니다. 이런 점은 분명 개선이 필요하다고 봅니다.
아래 코드는 제가 최근에 쓴 기사들을 감성(sentiment) 필터까지 넣어서 조회하는 함수입니다. 기본 조회에 정렬과 제한 개수도 쉽게 적용되니, 이런 간단한 조건부 조회는 손쉽게 해낼 수 있다는 게 확실한 장점입니다. 다만, 감성 필터를 넣을 때 쿼리가 꽤 무거워져서 요청 시간이 조금 늘어난 건 아쉬웠어요.
def get_recent_articles(limit: int = 10, sentiment: str = None) -> list:
"""최근 기사를 조회 — 감성 필터 옵션"""
query = supabase.table("articles")
.select("id, title, summary, sentiment, created_at")
.order("created_at", desc=True)
.limit(limit)
if sentiment:
query = query.eq("sentiment", sentiment)
response = query.execute()
return response.data
# 최근 긍정 기사 5건 조회
positive_news = get_recent_articles(limit=5, sentiment="긍정")
for article in positive_news:
print(f"[{article['sentiment']}] {article['title']}")사실 저는 Firebase를 쓰다 Supabase로 넘어온 케이스인데, Firebase는 쿼리 조건 조합이 훨씬 제한적이고 복잡한 필터링이 어렵다는 점 때문에 답답함이 컸습니다. Supabase는 PostgreSQL 기반이라 쿼리 자유도가 높은 건 분명한 장점인데, SDK의 메서드 체인이 모바일에서 완벽하지 않은 건 아쉬웠어요. 서버 환경에선 무난히 돌아가지만, 앱에서 바로 쓸 때는 예외 처리를 꼼꼼히 해야 할 겁니다.
데이터 삭제 (Delete)
제가 직접 운영하면서 느낀 건데, 오래된 기사를 자동으로 정리하지 않으면 데이터베이스가 금방 꽉 차서 곤란합니다. 특히 Supabase는 타임스탬프를 TIMESTAMPTZ 타입으로 저장하는데, 이게 UTC 기준이라 날짜 계산할 때 헷갈리기 딱 좋더군요. 그래서 저는 날짜 계산할 때 항상 datetime.utcnow()를 기준으로 쓰는데, 이 부분을 실수하면 의도치 않은 데이터를 삭제해서 진땀 뺐던 적도 있습니다. 그리고 삭제 후에 반환되는 데이터 길이로 삭제 건수를 바로 확인할 수 있어서 운영하면서 모니터링하기 편하더라고요.
def delete_old_articles(days_old: int = 30) -> int:
"""30일 이상 된 기사 자동 삭제"""
from datetime import datetime, timedelta
cutoff = (datetime.utcnow() - timedelta(days=days_old)).isoformat()
response = supabase.table("articles")
.delete()
.lt("created_at", cutoff)
.execute()
count = len(response.data)
print(f"{count}건 삭제 완료")
return count이 코드를 처음 돌릴 때는 모바일에서 메뉴가 꼬여서 한참 고생했어요. 삭제가 정상적으로 작동하는지 눈으로 확인하려고 했는데, UI가 제대로 반응하지 않아서 디버깅에 시간을 꽤 썼습니다. 그래서 자동화 스크립트로 돌리기 전에는 데이터가 잘 삭제되는지 꼭 수동으로 확인해보는 걸 추천합니다. 그리고 삭제 기준인 날짜를 바꿔가며 테스트할 때는 잘못 설정하면 너무 많은 데이터를 지워버려서 백업은 필수입니다. 저는 이 부분에서 실수한 적이 있어서, 여러분은 꼭 주의하세요.
4. 실제 마주친 에러 2가지와 대응 방법
에러 ① 프로젝트 접속 불가 — 7일 무활동 자동 정지 문제
출장으로 일주일 넘게 API 호출을 안 한 사이, 갑자기 자동화 봇이 멈춰서 깜짝 놀랐습니다. Supabase 무료 플랜은 7일 연속 아무 활동이 없으면 프로젝트를 자동으로 정지시키는 바람에, 대시보드에 들어가니 “Project paused due to inactivity”라는 메시지가 떡하니 뜨더군요. 복구는 [Restore project] 버튼만 누르면 2~3분 안에 되긴 했지만, 실제 서비스 중이었다면 사용자에게 꽤 치명적인 장애였을 겁니다. 그래서 이 문제를 막으려고 GitHub Actions에 SELECT 1 쿼리를 매일 실행하는 헬스체크 워크플로우를 넣었는데, 이것 덕분에 한 달 넘게 안정적으로 굴러가고 있습니다. 다만, 이 부분은 모바일 환경에서 특히 신경 써야 하는데, 모바일 앱에서 헬스체크가 꼬이거나 실패할 때가 많아 정말 짜증났던 기억이 납니다. 이런 자동 정지 기능 때문에 무심코 방치하면 금방 서비스가 멈출 수 있으니, 운영 중이라면 꼭 주기적으로 확인하는 습관을 들여야 합니다.
에러 ② RLS 정책 미설정으로 조회 데이터가 없던 문제
데이터를 테이블에 넣었는데, 파이썬 쪽에서 조회하면 빈 배열만 나오길래 한참 허둥댔습니다. 알고 보니 Supabase는 기본적으로 Row Level Security(RLS)가 켜져 있어서, 정책을 안 만들면 아무리 올바른 키를 써도 데이터가 보이지 않습니다. 이 사실을 몰라서 시간 낭비가 꽤 심했는데, SQL 에디터에서 anon 사용자에게 읽기와 삽입 권한을 명시적으로 줘야 정상 작동하더군요. 아래처럼 정책을 직접 만들어야 하는데, 이걸 빼먹으면 데이터가 들어가 있어도 외부에서 접근 못 해서 진짜 골치 아픕니다. 물론 보안을 위해선 무작정 권한을 다 풀기보다 세밀하게 조건을 걸어야 하지만, 초반에 이런 설정이 없으면 개발 막막해지는 건 확실합니다. 저처럼 삽질하지 말고 꼭 권한 정책 확인하세요.
-- anon 사용자에게 articles 테이블 읽기 허용
CREATE POLICY "Allow public read" ON articles
FOR SELECT USING (true);
-- anon 사용자에게 삽입 허용
CREATE POLICY "Allow public insert" ON articles
FOR INSERT WITH CHECK (true);5. 자동화 봇과 Supabase 연동 시 체감하는 변화
제가 직접 Supabase를 데이터 저장소로 붙여서 여러 자동화 파이프라인을 돌려봤는데, 확실히 전보다 안정성이 좋아졌다는 느낌입니다. 예를 들어 Gemini API 기반 뉴스 수집 봇은 매일 크롤링한 기사들을 데이터베이스에 쌓아두는데, 날짜별이나 키워드별로 원하는 뉴스 아카이브를 바로 꺼내볼 수 있어서 업무 효율이 꽤 올랐어요. 다만, 모바일 환경에서는 가끔 메뉴가 꼬이면서 데이터 조회가 원활하지 않아 짜증난 적도 있었습니다. 그리고 Whisper로 만든 강의 노트 봇은 음성 변환 후 요약한 내용을 Supabase에 저장하는데, 영상 URL 중복 처리를 자동으로 해줘서 중복 작업을 줄이는 데 이만한 게 없었습니다. 그래도 한두 번은 중복 체크가 누락돼서 수동으로 확인하느라 시간을 좀 낭비하기도 했네요. 이런 점들을 감안하면 Supabase가 단순 저장소 이상의 역할을 하면서도 아직 개선할 여지가 꽤 있다는 걸 체감했습니다.